
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝공부
- feature scaling
- 자바시작하기
- 자바강좌
- Python강의
- 머신러닝공부
- 백준 알고리즘
- Gradient Descent
- 파이썬강의
- 비용함수
- 파이썬강좌
- 머신러닝 강의
- acmicpc.net
- unsupervised learning
- python강좌
- 머신러닝
- 자바
- supervised learning
- 코딩테스트
- 경사하강법
- 지도학습
- 선형회귀
- 딥러닝
- 머신러닝 강좌
- 비지도학습
- JAVA강좌
- java
- c언어 오목
- 효묘블로그
- 인공지능
- Today
- Total
컴공과컴맹효묘의블로그
DBSCAN을 이용한 식당 리뷰 요약 서비스 본문
4학년 졸업 작품으로 맛집 검색 서비스를 개발하고있었다. 맛집 검색이라는 서비스는 이미 수년 전에 많은 사람들이 했던 진부한 그런 프로젝트였다. 리뷰 요약 서비스는 이 서비스에서 뭔가 특별한 우리만의 서비스는 없을까 고민하다가 나온 아이디어다.
대부분의 사람들은 식당 선택에 있어 때 별점과 리뷰를 결정적인 요인으로 보는 경향이 있다(1). 나 또한 경험적으로 1차로 별점을 확인하고, 2차로 리뷰를 확인한다.
기술
- Language: Python
- Framework: FastAPI
- Architecture: Docker, Spring Cloud
- KoNLPy(Okt): 한국어 형태소 분석 및 어간 추출
- 감정 사전(SentiWord_Dick.txt): 단어별 polarity 점수
- Sentence-Transformers(‘jhgan/ko-sbert-sts’): 한국어 문장 임베딩
- scikit-learn DBSCAN: 클러스터링
requirements.txt
fastapi==0.110.0
torchvision==0.20.1
uvicorn==0.29.0
pandas==2.2.3
konlpy==0.6.0
ko_sentence_transformers==0.3흐름도
API 엔드포인트 → 데이터 전처리 → 감성 분석 → 문장 임베딩 → 클러스터링 → 결과 응답
RequestBody 정의
class ReviewList(BaseModel):
content: List[str]형용사, 명사 추출 함수 정의
형용사와 명사를 추출하는 함수를 정의합니다.
이 함수는 나중에 감성분석을 활용하기 위함입니다.
def lemmatize(sentence: str):
morphtags = okt.pos(sentence, stem=True) # 어간만 추출
words = []
for m, t in morphtags:
if t == 'Adjective' or t == 'Noun':
words.append(m)
return words💡
Tip: 한국어는 조사나 어미가 다양하기 때문에 어간(stem)만 추출해 두면, 감성 사전과 비교할 때 단어 매칭률이 높아집니다.
감성 사전 로드 및 딕셔너리 생성
군산대학교에서 구축한 감성 사전을 로드합니다. 이는 표준어 대사전과 그 외의 축약어, 이모티콘 등 표준어 대사전에는 없는 새로운 감성어까지 포함하고 있기 때문에 식당 리뷰에 적당할 것 같아서 사용했습니다.
https://github.com/park1200656/KnuSentiLex
f = pd.read_csv('./KnuSentiLex/SentiWord_Dict.txt', sep='\t', header=None, names=['emoticon', 'polarity'])
sentiment_dictionary = f.set_index('emoticon')['polarity'].to_dict()SentiWord_Dict.txt 파일은 단어-점수 쌍으로 TSV 형식으로 이루어져있는 파일입니다.

KnuSentiWord 감성 사전을 다운 받고 Pandas로 읽어온 후 각 컬럼을 emoticon과 polarity로 지정해줍니다.
이후 emoticon을 인덱스로 지정해줍니다.
f = pd.read_csv('./KnuSentiLex/SentiWord_Dict.txt', sep='\t', header=None, names=['emoticon', 'polarity'])
sentiment_dictionary = f.set_index('emoticon')['polarity'].to_dict()리뷰 가져오기
이제 리뷰를 불러와야합니다. 리뷰를 불러오기 위해서는 DB에 접근해서 리뷰를 쿼리로 가져오는 것이 가장 빠를 것입니다. 하지만 테스트를 위해 미리 특정 식당을 크롤링하여 “naver_review_2024-11-09_16-55-54.xlsx”라는 이름으로 저장했습니다.
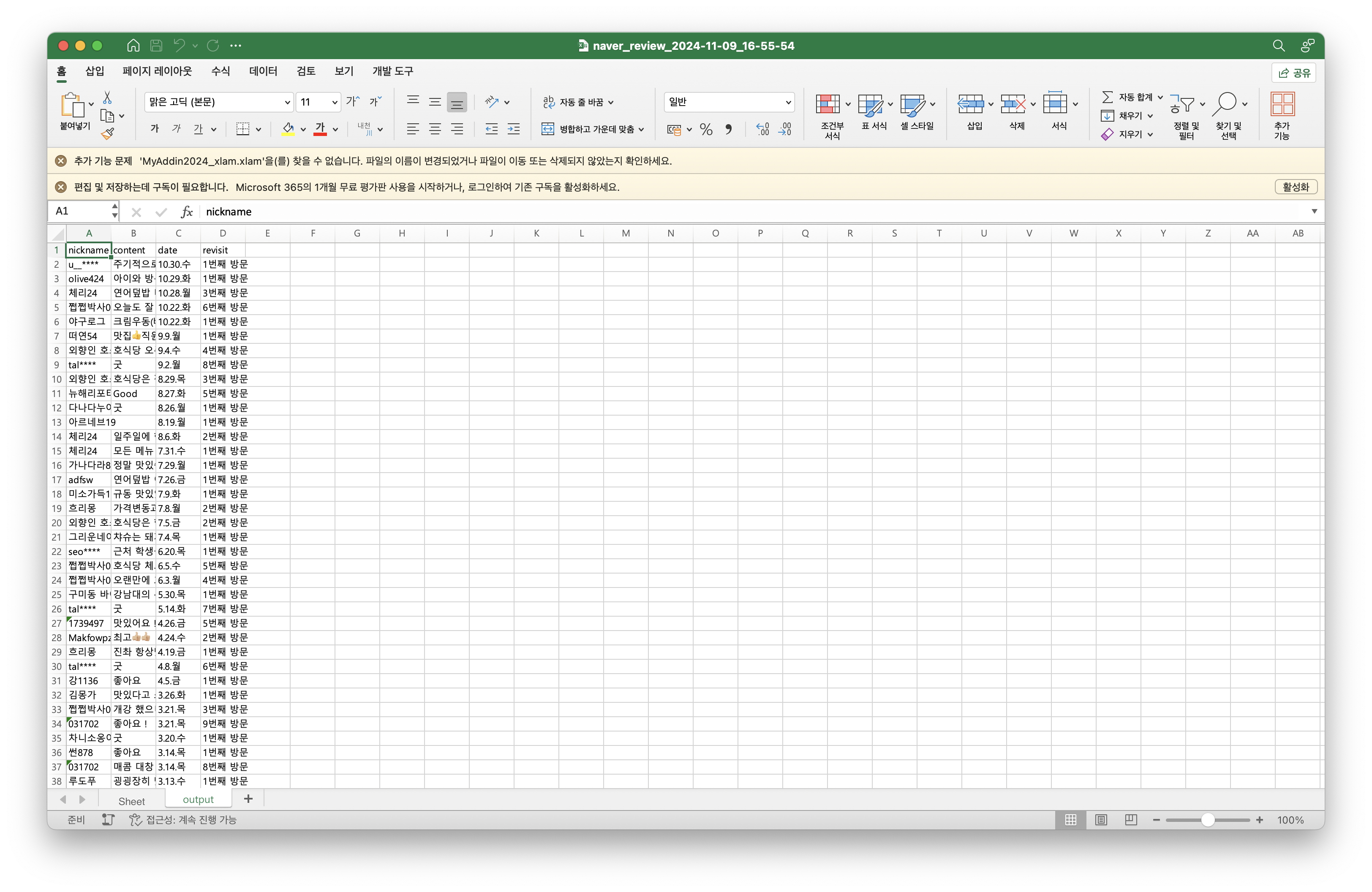
# 크롤링한 파일 읽기
wb = pd.read_excel('naver_review_2024-11-09_16-55-54.xlsx', sheet_name="output")
# 리뷰만 가져오기
review = wb[['content']]크롤링 한 결과를 “output” sheet에 저장했기 때문에 “sheet_name”을 지정해줍니다. 또한 리뷰만 사용할것이기 때문에 리뷰만 따로 가져옵니다.
리뷰가 없는 행은 제거하기 위해 결측치 처리를 해줍니다.
review = review.dropna(subset=['content'])명사 추출
감성 분석을 위해서 어간을 추출하여 words 컬럼에 넣습니다.
# 명사 추출
n_= []
# 명사 + 형용사만 추출한 키워드 컬럼. 그저 시각적으로 남기기 위해 생성.
for text in review['content']:
nouns = [m for m, pos in okt.pos(text) if pos in ['Noun', 'Adjective']]
n_.append(' '.join(nouns))
review['nouns'] = n_
review = review[review['nouns']!=''].reset_index(drop=True)
# 어간 추출 함수로 words 컬럼 생성.
w_ = []
for text in review['content']:
words = lemmatize(text)
w_.append(' '.join(words))
review['words'] = w_출력 예시
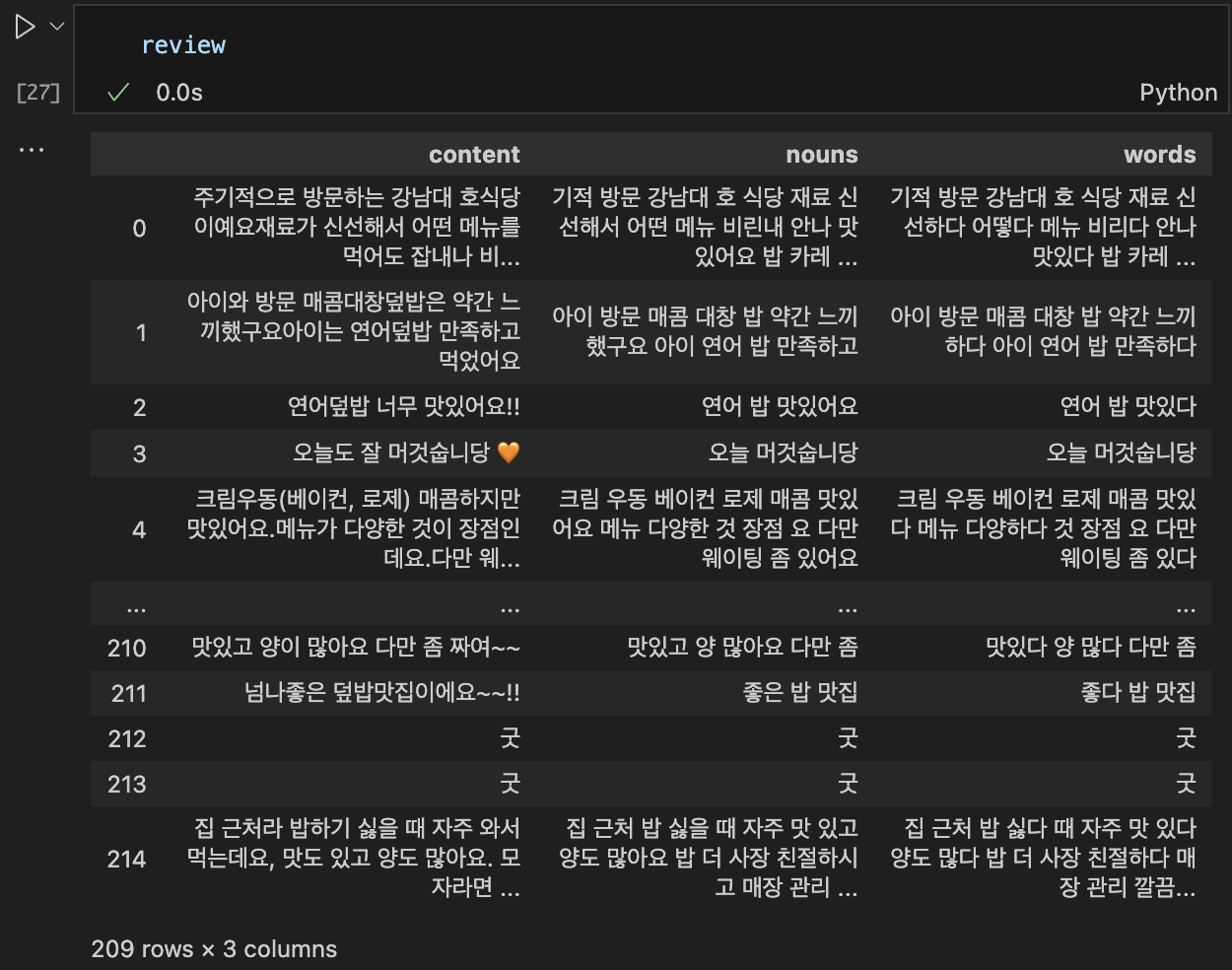
감성 분석
감성이 없는 중립적인 리뷰는 건너 뛰고 부정적 혹은 긍정적인 리뷰만 남기기 위해서 감성분석을 수행합니다.
total = []
for i, w in enumerate(review['words']):
sent_score = 0
w = w.split(' ')
for j in w:
# 한 글자 혹은 감성단어 사전에 없으면 무시
if len(j) <= 1 or j not in sentiment_dictionary:
continue
else:
sent_score = sent_score + float(sentiment_dictionary[j])
total.append(sent_score/len(w))
# 'sent_score' 컬럼 추가
review['sent_score'] = total
# 감성 점수가 0인 리뷰 제외
review_df = review[review['sent_score'] != 0.0]문장 임베딩(SBERT) 적용
문장 임베딩을 수행합니다. 한국어 구문간 유사도에 특화된 SBERT 모델을 사용합니다.
# Ko-SBERT 모델 로드
embedder = SentenceTransformer('jhgan/ko-sbert-sts')
# 리뷰 문장 리스트
k = review_df.content.to_list()
# 임베딩 수행 (각 차원을 768차원 벡터로 변환)
if review_df.size == 0:
return []
review_one_embeddings = embedder.encode(k)- ep=0.25: 두 문장 임베딩 간 코사인 거리가 0.25 이내이면 이웃 으로 간주합니다.
- min_smaple=6: 최소 6개 샘플이 모여야 하나의 클러스터로 형성합니다.
- metric=”cosine”: 코사인 유사도를 거리로 사용합니다.
# DBSCAN 모델 정의 (코사인 유사도 거리 사용)
model = DBSCAN(eps=0.25, min_samples=6, metric="cosine")
# 리뷰 임베딩 벡터에 대해 클러스터링 수행
cluster2 = model.fit_predict(review_one_embeddings)
# 결과를 DataFrame에 컬럼으로 추가
review_df['dbscan'] = cluster2
res = []
print('Total Clustering num: {}'.format(len(set(cluster2))-1))
for cluster_num in set(cluster2):
if cluster_num == -1: # 잡음 건너 뜀
continue
else:
print("Cluster num: {}".format(cluster_num))
temp_df = review_df[review_df['dbscan'] == cluster_num]
print(temp_df.iloc[0]['content'])
res.append(temp_df.iloc[0]['content'])
for content in temp_df['content'][:3]:
print(content)
print()
return res출력 예시
네이버에서 리뷰를 크롤링하여 얻은 결과를 출력해보았습니다.
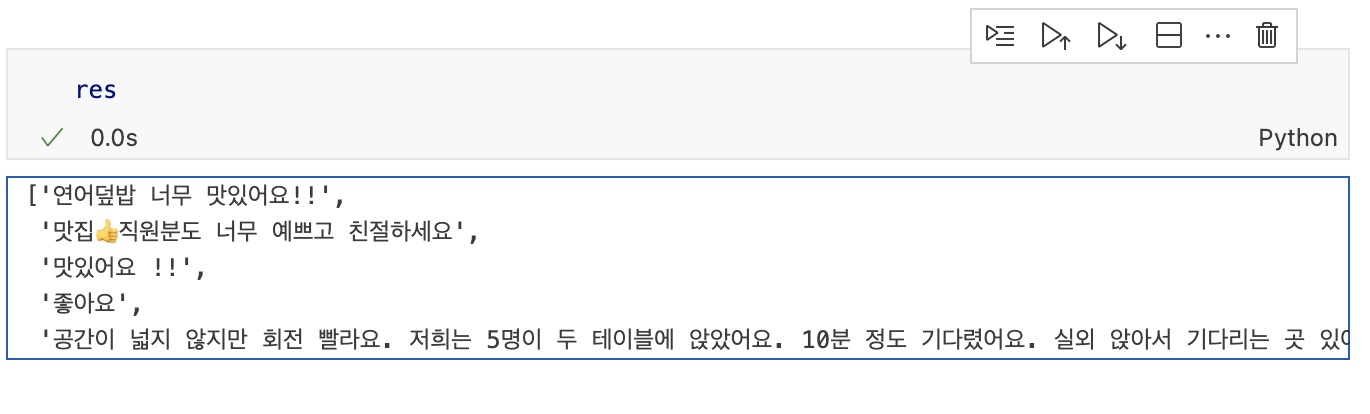
그 결과 위와 같은 리뷰 5개를 얻을 수 있었습니다. 공통적으로 중복된 의견들을 묶어서 보여주기 때문에 리뷰의 공통적인 내용을 한 번에 확인할 수 있다는 장점을 볼 수 있었습니다.
실제로 위와 같은 내용이 반복되는지 wordcloud 시각화로 확인해보겠습니다. wordcloud에서 단어 빈도수를 기준으로 출력해보겠습니다.
WordCloud 설치
!pip install wordcloudimport 추가
Counter는 단어의 빈도수를 계산하기 위해 필요합니다.
from wordcloud import WordCloud
from collections import Counter
import matplotlib.pyplot as plt단어 카운트
review에서 추출해놓았던 nouns 컬럼을 이용하여 명사 리스트 변수 nouns_words를 정의합니다.
Counter로 noun_words의 개수를 세어줍니다.
wordcloud_text = ' '.join([i for i in review['nouns']])
noun_words = wordcloud_text.split()
count = Counter(noun_words)
words = dict(count.most_common())
print(words)
출력 결과입니다.
{'밥': 67,
'맛있어요': 53,
'굿': 38,
'좋아요': 38,
'연어': 34,
'카레': 29,
'맛': 19,
'맛집': 18,
...
'맛있었어오': 1,
'싫을': 1,
'관리': 1,
'같고': 1,
'여럿': 1}WordCloud 출력
font_path = '/System/Library/Fonts/Supplemental/AppleGothic.ttf'
wordcloud = WordCloud(font_path=font_path, background_color='white').generate_from_frequencies(words)
plt.figure()
plt.axis('off')
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()

결론
식당에 대한 사람들의 평가를 리뷰 데이터를 이용하여 공통적인 내용만 추리고, 그 정보를 한 번에 제공할 수 있는 방법을 고민했습니다. 가장 편한 방법은 최근 많이 사용되는 ChatGPT나 Gemini같은 LLM API를 이용하여 리뷰 데이터를 한 번에 요약해달라고 요청하면 특별한 스킬 없이도 간단하게 해결할 수 있습니다. 하지만 그런 방법은 오버 엔지니어링이라고 생각했고, 또한 LLM의 편의성에 기대고 싶지 않았기 때문에 다른 방법을 생각해보았습니다.
AI 개발을 해보지 않아 개념에 무지한 상태에서 막연히 요약 서비스를 만들고 싶다는 생각에 인터넷을 뒤져보고 공부했습니다. 처음에는 리뷰 자체를 가볍게 Summarization하여 요약 문장을 생성 해보는 방법을 선택했지만, 방법이 잘못 된 것인지 요약 결과가 문법이 맞지 않는 어떤 문장으로 출력하듯이 원하는 결과가 나오지 않아 생성형을 버리고 리뷰의 공통적인 부분을 보는 클러스터링 방법으로 우회했습니다.
이 방식의 단점은 그저 "맛있습니다" 혹은 "좋아요"같은 단순한 리뷰가 대표 리뷰로 선택될 가능성이 많고, 클러스터링 된 각 집합에 대해 대표 리뷰를 선택해야한다는 것에 있습니다. 결국 이 문제를 해결하려면 각 집합의 요약이나 대표 리뷰를 선택해야하고 이는 Generative AI를 사용할 수 있음을 의미합니다.
위 리뷰는 약 200개의 리뷰 데이터로 클러스터링을 진행했습니다. 제 컴퓨터로 리뷰 200개 기준으로 클러스터링을 수행하는데 약 4.7초가 걸렸습니다. Gemini와 같은 무료 API를 사용하면 10초 이상이 걸리므로 시간적으로는 200%의 효율을 보여줍니다.
전체 코드
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
import pandas as pd
from konlpy.tag import *
from sentence_transformers import SentenceTransformer
# Clustering
from sklearn.cluster import DBSCAN
app = FastAPI()
class ReviewList(BaseModel):
content: List[str]
okt = Okt()
# 형용사를 명사로.
def lemmatize(sentence: str):
morphtags = okt.pos(sentence, stem=True)
words = []
# print(morphtags)
for m, t in morphtags:
if t == 'Adjective' or t == 'Noun':
words.append(m)
return words
@app.post("/contents/review")
async def review(review_list: ReviewList):
df = pd.DataFrame(review_list.content, columns=["content"])
f = pd.read_csv('./KnuSentiLex/SentiWord_Dict.txt', sep='\t', header=None, names=['emoticon', 'polarity'])
# print(f)
sentiment_dictionary = f.set_index('emoticon')['polarity'].to_dict()
pd.DataFrame(list(sentiment_dictionary.items()), columns=['emoticon', 'polarity']).to_csv('SentiWord_tocsv.csv', index=False)
sentiment_dictionary=pd.read_csv('./SentiWord_tocsv.csv', header=None, index_col=0).squeeze().to_dict()
# 리뷰 읽기
wb = pd.read_excel('naver_review_2024-11-09_16-55-54.xlsx', sheet_name="output")
# review = df
review = wb[['content']]
# 분석기 객체 생성
okt = Okt()
# 결측치 제거
review.dropna(subset=['content'])
review = review.dropna()
print(review)
# 명사 추출
n_= []
for i in range(len(review)):
nouns = [x[0] for x in okt.pos(review.iloc[i].content) if x[1] in ['Noun', 'Adjective']]
n_.append(' '.join(nouns))
review['nouns'] = n_
review = review[review['nouns']!='']
w_ = []
for i in range(len(review)):
words = lemmatize(review.iloc[i].content)
w_.append(' '.join(words))
review['words'] = w_
# 감성분석
total = []
for i, w in enumerate(review['words']):
sent_score = 0
w = w.split(' ')
for j in w:
if len(j) <= 1 or j not in sentiment_dictionary:
continue
else:
sent_score = sent_score + float(sentiment_dictionary[j])
total.append(sent_score/len(w))
review['sent_score'] = total
review_df = review[review['sent_score'] != 0.0]
# 문장 임베딩
embedder = SentenceTransformer('jhgan/ko-sbert-sts')
k = review_df.content.to_list()
if review_df.size == 0:
return []
review_one_embeddings = embedder.encode(k)
model = DBSCAN(eps=0.25, min_samples=6, metric="cosine")
cluster2 = model.fit_predict(review_one_embeddings)
review_df['dbscan'] = cluster2
res = []
print('Total Clustering num: {}'.format(len(set(cluster2))-1))
for cluster_num in set(cluster2):
if cluster_num == -1:
continue
else:
print("Cluster num: {}".format(cluster_num))
temp_df = review_df[review_df['dbscan'] == cluster_num]
print(temp_df.iloc[0]['content'])
res.append(temp_df.iloc[0]['content'])
for content in temp_df['content'][:3]:
print(content)
print()
return res'컴퓨터 > 머신러닝' 카테고리의 다른 글
| k-means 알고리즘 python으로 구현해보기 (2차원 데이터 시각화) (0) | 2020.04.25 |
|---|---|
| 수알못의 머신러닝 공부 : Logistic Regression을 이용한 Classification을 Python으로 구현 (0) | 2020.04.02 |
| 수알못의 머신러닝 : 선형회귀 - normal equation 정규방정식 (0) | 2019.08.23 |
| Polynomail Regression 다항식 회귀 (0) | 2019.08.19 |
| 머신러닝 회귀 분석 Feature Scaling (0) | 2019.08.19 |



